

Op 21 februari publiceerde de Volkskrant een artikel met de titel ‘Het prof. dr. Dagobert Duck-effect’. Dat moet aantonen of onderzoeksgeld wel of niet eerlijk verdeeld wordt. Een drietal journalisten heeft daartoe de gegevens van NWO uitgeplozen om te zien naar wie het meeste geld gaat van onderzoekssubsidies die door de overheid veelal via competitieve programma’s verdeeld worden. De teneur van het stuk is duidelijk: een groot gedeelte van het geld gaat naar een beperkt deel van de onderzoekers en ‘dus’ deugt het systeem niet want de ‘Grote Graaiers’ zouden bijna alles krijgen. Hierbij wordt een serietje beknopte interviewtjes met ‘have’s’ and ‘have not’s’ gevoegd dat een en ander plausibel moet maken.
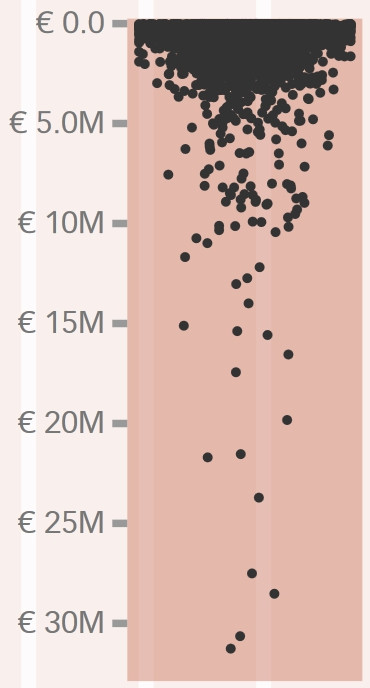 Gelukkig ben ik wat sceptisch ingesteld en kijk ik graag zelf eens naar de ruwe data. De website waarop het Volkskrantartikel staat geeft in een mooie figuur (rechts) weer wat de verdeling is, en je kunt zelf op individuele punten klikken waarbij je naam en bedrag kunt zien. Zo ook van enkele prominente UT-ers: de echte grootverdieners zijn, wellicht niet verrassend, Albert van de Berg en Detlef Lohse, maar er staan ook vele anderen bij. De belangrijke vragen zijn natuurlijk: is dit een vreemde verdeling? En is het een ongewenste verdeling?
Gelukkig ben ik wat sceptisch ingesteld en kijk ik graag zelf eens naar de ruwe data. De website waarop het Volkskrantartikel staat geeft in een mooie figuur (rechts) weer wat de verdeling is, en je kunt zelf op individuele punten klikken waarbij je naam en bedrag kunt zien. Zo ook van enkele prominente UT-ers: de echte grootverdieners zijn, wellicht niet verrassend, Albert van de Berg en Detlef Lohse, maar er staan ook vele anderen bij. De belangrijke vragen zijn natuurlijk: is dit een vreemde verdeling? En is het een ongewenste verdeling?
Zipf's Law
Nu is er een wetmatigheid die onder de naam ‘Zipf’s Law’ bekend staat. Deze ‘wet’ is voor het eerst gevonden in de taalkunde (om maar met een alfawetenschap te beginnen) en zegt dat als je een ranglijst van de in een taal gebruikte woorden maakt, een woord op die ranglijst ongeveer twee keer zo veel gebruikt wordt als het twee keer zo hoog op de ranglijst staat.
Voor de beta-ingestelde nerds onder ons: zet de logaritme van het rangnummer uit tegen de logaritme van het woordgebruik en je vindt een rechte lijn met een steilheid van 1. Merkwaardig genoeg is die wetmatigheid ook gevonden in tal van andere gebieden, bv. voor de bevolkingsaantallen van Amerikaanse steden (zie de figuur hieronder)., en ook met een steilheid van 1.
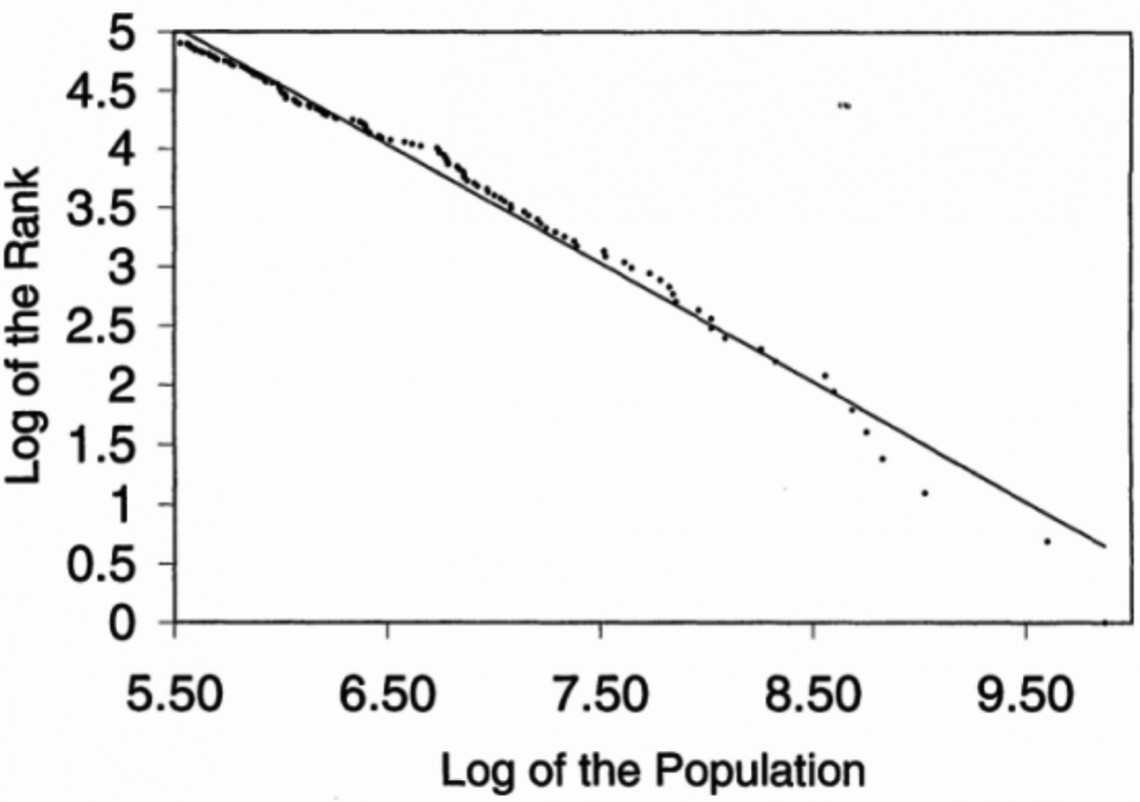
Zipf’s Law toegepast op de bevolkingsaantallen van Amerikaanse steden (bron: http://io9.com/the-mysterious-law-that-governs-the-size-of-your-city-1479244159).
Nederlandse nivellering?
Terug naar de onderzoekssubsidies: een beetje huisvlijt van het breedste deel van de verdeling (de Volkskrant was, ondanks contactpogingen van mijn kant, niet genegen mij de lijst zelf te sturen) en omzetten in een log-log plot geeft ook hier een lineair verband (zie de figuur hieronder). Hoera, Zipf’s Law geldt ook voor de (onderzoekssubsidie) economie! Dat is wellicht nog niet zo bijzonder, maar de steilheid is dat wel: die is 1.6, dwz dat iemand die twee keer zo hoog op de ranglijst staat niet twee keer zoveel subsidie heeft ontvangen, maar ‘slechts’ anderhalf keer. Die afhankelijkheid is dus heel wat zwakker dan voor spontane, onbewuste processen als woordgebruik en stedengroei! Is dit de Nederlandse nivellering?
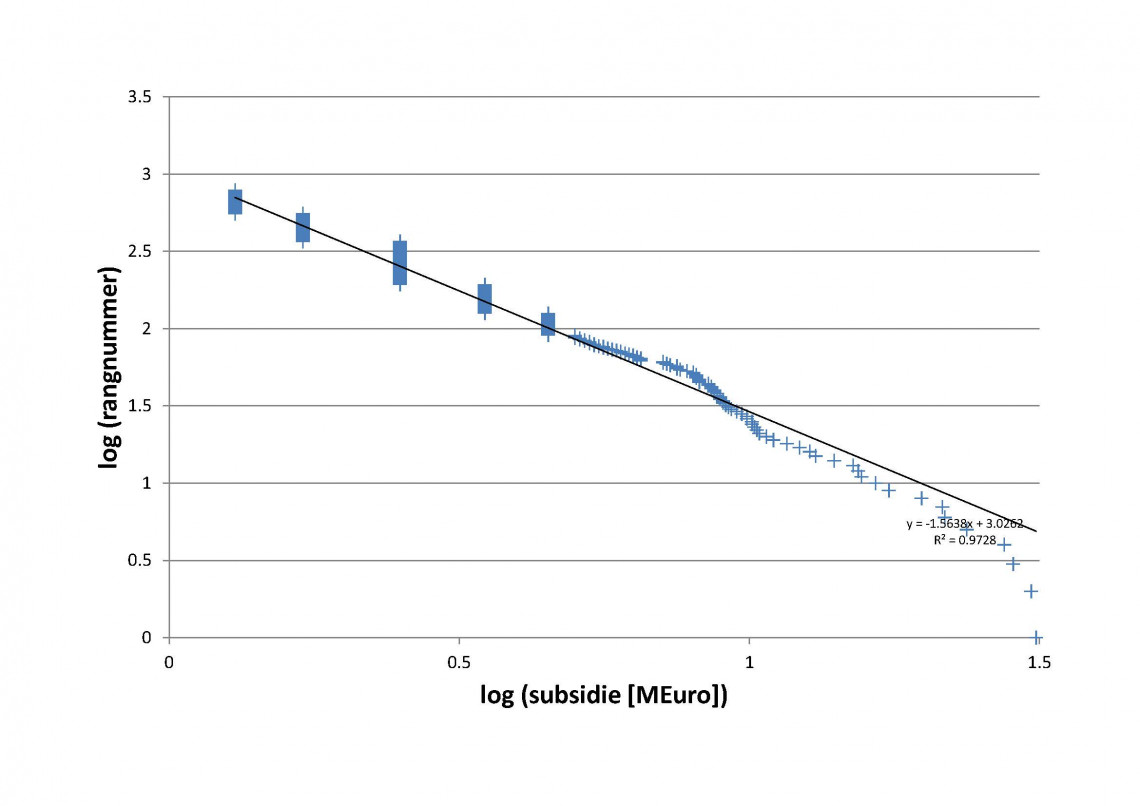
Zipf’s Law toegepast op de Nederlandse onderzoekssubsidies (deel van de data van het Volkskrantartikel: alle punten boven de 5 M€ expliciet, van 1.2-5.0 M€ in 5 bins; <1.2 M€ niet meegenomen).
How to lie with statistics
Kortom, de verdeling zegt me bar weinig, en zal meer met de wetenschaps-journalistieke cursus ‘How to lie with statistics’ te maken hebben die de schrijvers wellicht gevolgd hebben, want de uitleg van de data is niet eenduidig. Serieuzer echter is natuurlijk wel welke subsidies er zijn, in welke porties het geld verdeeld wordt en hoe die verdeling tot stand wordt gebracht.
De grote uitschieters (boven de paar miljoen in de grafiek) worden vrijwel allemaal veroorzaakt door slechts één programma, NWO Zwaartekracht. Aangezien het voornaamste selectiecriterium daar lijkt te zijn geweest of je wel of niet al eerder een Spinozaprijs of een ERC Advanced grant ontvangen had, kun je daaraan wél zien dat eerdere subsidies en prijzen een versterkend effect hebben op de totale subsidieomvang van een onderzoeker.
Wet van Huskens
Dat is niet noodzakelijkerwijs slecht, want past performance is nog altijd de beste indicator voor future performance. Maar de porties geld die er in dit specifieke geval mee gepaard gaan en de ondoorzichtigheid van de hele procedure hebben de Nederlandse wetenschap en NWO geen goed gedaan. En dit heeft zich al eerder voorgedaan bij heel grote programma’s. Als je dat afzet tegen de moeite die onderzoekers moeten doen om een kleine subsidie binnen te halen (vaak via eerst een preproposal, eerste schifting, dan een full proposal, met daarna wellicht weer een schifting en een interview) en de geringe slaagkans daarvan, is het verschil schrijnend.
Daarom wil ik afsluiten met de verder niet wiskundig of met data onderbouwde Wet van Huskens: ‘De omvang van de subsidie is omgekeerd evenredig met de helderheid van het proces waarmee de subsidie verdeeld wordt’.




